
Verarbeitung von Datenströmen im Big Data Umfeld
Implementierung und Evaluierung einer Verarbeitung von Datenströmen im Big Data Umfeld am Beispiel von Apache Flink,
Implementierung und Evaluierung einer Verarbeitung von Datenströmen im Big Data Umfeld am Beispiel von Apache Flink,
Seit knapp drei Jahren arbeiten wir gemeinsam mit unserem Kunden, der SV SparkassenVersicherung, an Use Cases im Big Data Umfeld. Begonnen hat das Projekt mit dem Aufbau eines Big Data Labors im Jahr 2018, in dem der Kunde erste Erfahrungen mit Big Data und dem Einsatz Künstlicher Intelligenz (KI) sammeln konnte.
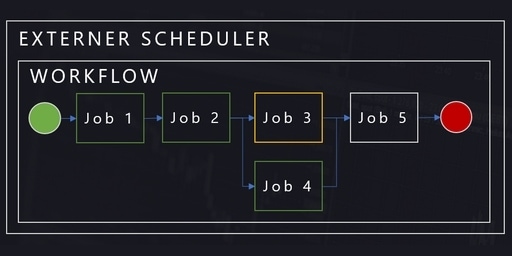
In einer von uns ausgeschriebenen und betreuten Abschlussarbeit, wurden verschiedene Optionen für das Scheduling von ETL-Prozessen, welche mit Informatica PowerCenter umgesetzt sind, untersucht. In diesem zweiten Beitrag zum Thema zeigen wir die Erkenntnisse, die durch die Arbeit gewonnen werden konnten.
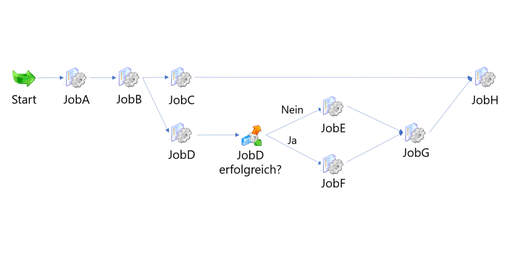
ETL-Prozesse bestehen mitunter aus einer Vielzahl von ETL-Aktivitäten, zwischen denen komplexe Abhängigkeiten existieren können. Zur Orchestrierung eines korrekten Ablaufs der einzelnen ETL-Aktivitäten werden sogenannte Scheduling-Tools eingesetzt. In einer von uns ausgeschriebenen und betreuten Abschlussarbeit, wurden verschiedene Optionen für das Scheduling von ETL-Prozessen, welche mit Informatica PowerCenter umgesetzt sind, untersucht.
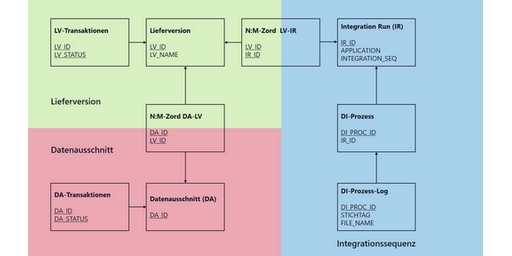
Große Banken müssen jederzeit in der Lage sein, ihre verschiedenen Risikobereiche zu überblicken und an die zuständige Aufsicht zu melden. Die entsprechenden Daten müssen nicht nur aktuell, sondern auch hochwertig sein. Damit dieser Datenhaushalt metadatengetrieben und qualitätsgesichert verwaltet werden kann, nutzen unsere Berater Lieferversionen und Datenausschnitte.

Die zeitliche Verfügbarkeit von Informationen wird durch digitale Transformationen immer wirchtiger. In der aktuellen Ausgabe der BI-Spektrum stellt Matthias Hoffmann, Partner bei integration-factory, einen innovativen und auf Big Data-Technologie basierenden Ansatz für die Umsetzung einer ganzheitlichen Streaming-Strategie vor.
Seit dem ersten produktiven Prozess im Data Warehouse der EEX (BDWH) sind nun 5 Jahre vergangen. Von anfänglich 124 täglichen Prozessen vergrößerte es sich in dieser Zeit auf ca. 75.000!

Mit drei Kollegen war integration-factory dieses Jahr auf der Data Driven Business Konferenz in Berlin vertreten. Das Event vereint drei verschiedene Schwerpunkte, sodass wir uns umfangreich über aktuelle Themen in den Bereichen Marketing, Customer Journey und Data Analytics informieren konnten.

Auf der diesjährigen Informatica World Tour stellen integration-factory und DZ Bank AG die Architektur des Financial Data Warehouse vor. Die Konferenz findet in Frankfurt statt und bietet ein vielseitiges Programm mit Keynotes, Technical Breakouts und Best Practices Tracks.