Dass Daten zu einem der wichtigsten Rohstoffe für Unternehmen geworden sind, ist selbstverständlich. Wir helfen Ihnen, den Weg zum datengetriebenen Unternehmen erfolgreich zu beschreiten.
Das datengetriebene Unternehmen trifft Entscheidungen nicht nach dem Bauchgefühl. Vielmehr nutzt es alle erreichbaren internen und externen Daten, investiert in Datenkompetenz und trifft Geschäftsentscheidungen auf Basis von Daten.
Der Erfolg dieser Investitionen lässt sich in der Regel leicht ablesen, weil datengetriebene Unternehmen…
Wir sind auf die Konzeption und Umsetzung innovativer Data Management-Lösungen fokussiert. In unseren Schwerpunktthemen Cloud & Big Data, Data Warehousing und Data Governance haben wir eine Vielzahl erfolgreicher Projekte durchgeführt. Die erlangte Expertise haben wir systematisiert und bringen Best Practices, praxiserprobte Methoden und ein zielgerichtetes Vorgehen in die strategische Beratung ein.

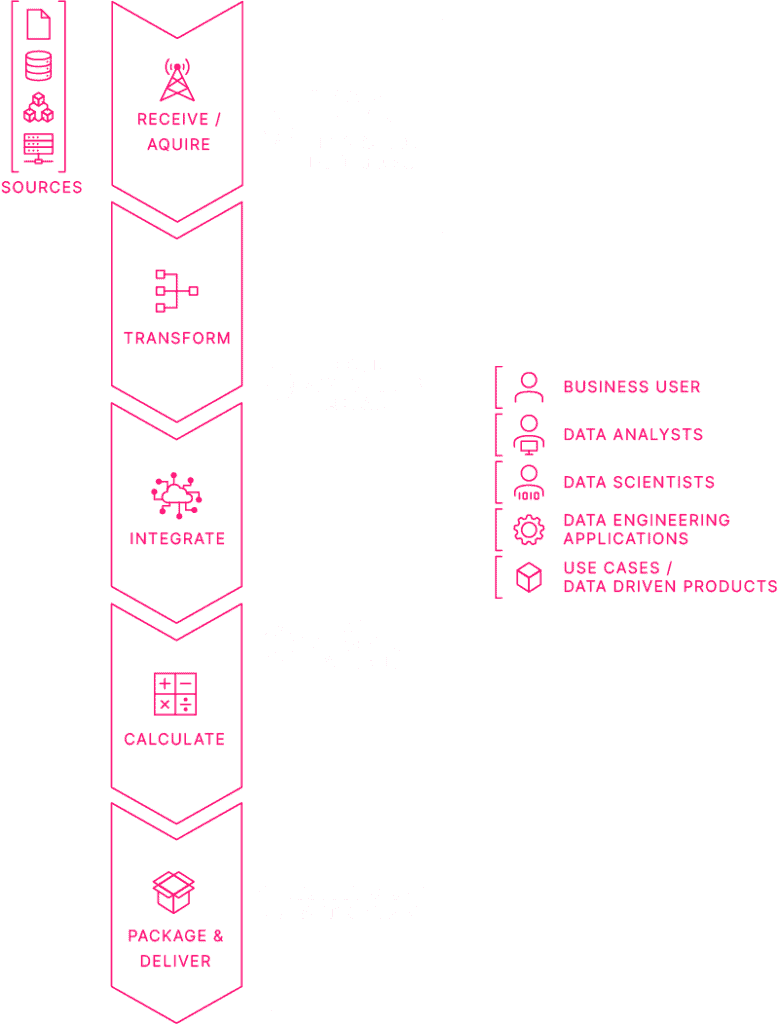



Die Aufgabe der Datenintegration ist die Aufbereitung verteilt vorliegender, heterogener interner und externer Unternehmensdaten, so dass diese auf smarte Weise für Datenanalysen, Entscheidungsfindungen und zur Unterstützung automatisierter Geschäftsprozesse verwendet werden können.
Datenintegration stellt die Schlüsseltechnologie jeder Digitalisierungsstrategie dar und ist somit das Kernelement für Big Data und Data Warehouse Systeme, aber auch elementar für alle Anwendungsgebiete, in denen das Zusammenführen von Daten grundlegend ist.
Direkt adaptierbare Pattern
Modular einsetzbare Funktionsbausteine
Der integration-factory Pattern Approach ermöglicht es, mit kleinen Teams große Systeme in homogener Qualität schnell zu realisieren. Der Pattern Approach ist eine skalierbare Methode für den effizienten Aufbau von großen Daten-managementsystemen und ermöglicht, das ganze Potenzial der eingesetzten Werkzeuge und der getätigten Investition auch wirklich zu nutzen.
Der wesentliche Vorteil des Pattern Approach besteht darin, dass Design, Entwicklung und Test der (Kern-)Funktionalität nur genau einmal je Pattern erfolgt. In der N-fachen Anwendung eines Patterns werden dann nur noch die Instanz-Eigenschaften wie bspw. die konkreten Kundendatenfelder angewandt. Diesen Vorgang bezeichnen wir auch als Instanziierung. Es entstehen N lauffähige Prozesse, auf die sich Design, Entwicklung und die getestete Qualität des Patterns gleichermaßen vererben.
Unser Cloud-Service MetaKraftwerk ist die automatisierte Anwendung des Pattern Approach. Mit MetaKraftwerk entfällt der manuelle Entwicklungs-aufwand vollständig. Da die erzeugten Instanzen ausschließlich auf Basis von Metadaten und der maschinellen Anwendung von Regeln erzeugt werden, sind Abweichungen vom Pattern ausgeschlossen. Es bleibt ein geringer Testaufwand, der lediglich den Einfluss der Instanz-Metadaten abprüft.
Auch in Zeiten von Cloud, Big Data und Schema on Read ist das Thema Datenmodellierung und der elegante Umgang mit verschiedenen Zeitdimensionen äußerst wichtig für Data Management-Lösungen.
Der Data Lake mit seinen verschiedenen Zonen bietet die optimale Ablage empfangener und für Data Science und Data Analytics aufbereiteter Daten. Ein Data Warehouse ist die Plattform, auf der Daten ein Schema besitzen, das optimal die Aspekte Datenablage bzw. -haltung und Datennutzung unterstützt.
Das klassische Data Warehouse leistet bereits seit Jahren gute Dienste. Technologisch, inhaltlich und funktional hat sich die Welt aber weitergedreht. Dies bietet Chancen, ein bestehendes System erfolgreich auf die nächste Stufe zu heben und so von neuen, modernen Ansätzen zu profitieren.
Wenn Sie dabei Kostenexplosionen und lange Stilllegungen oder eine gedrosselte Innovationskraft vermeiden wollen, dann sind wir der ideale Partner für Sie.
Wissen ist der Schlüssel zu geschäftlichem Erfolg und Daten, die rechtzeitig und richtig analysiert werden, sind die Grundlage smarter und guter Entscheidungen im Lichte des Wettbewerbs. Mit einem modernen Cloud Data Warehouse sind Unternehmen in der Lage, mehr relevante Daten als in traditionellen Data Warehouses zu speichern und zu organisieren. Dies umfasst eine große Bandbreite interner und externer Quellen strukturierter und semi-strukturierter Daten – einschließlich Datamarts, Cloud-basierter Applikationen und Maschinendaten.
Daten sind der Rohstoff des 21. Jahrhunderts. Entsprechend stehen Data Management Projekte im Fokus. Zentrale Komponente ist immer die Datenintegration und häufig werden metadatengetriebene Datenintegrations-tools wie Informatica für den Aufbau eingesetzt. Ein Großteil der Projektkosten fällt bei der Umsetzung und im Test der Datenintegrationsprozesse an.
Hier setzen wir an – ob in bestehenden Systemen, für die die Anwendungsentwicklung verschlankt, agiler und qualitativ verbessert werden soll oder in neuen Projekten, bei denen von Beginn an auf weitestgehende Entwicklungseffizienz gesetzt werden soll.
Analytisch auf neusten, im besten Fall auf Streamingdaten und damit auf gerade eben entstandenen Daten arbeiten zu können, ist für viele geschäftskritische Fragestellung, Entscheidungen und operative Prozesse und vor dem Hintergrund eines exponentiell steigenden Datenvolumens äußerst bedeutungsvoll.
Das Data Warehouse – on-premises oder als modernes Cloud Data Warehouse – stellt die kanonische Lösung zur Integration historischer operativer und weiterer geschäftskritischer Daten in einem konsistenten, homogenen Datenhaushalt dar.
Technische Architektur, Datenmodellierung, Entwicklung von Datenintegrationsprozessen und Datentransformationsprozessen
Eurex Repo ist ein führender europäischer Marktplatz für besicherte internationale Finanzierungsgeschäfte. Der von Eurex Repo organisierte hochliquide Marktplatz verbindet den elektronischen Handels mit der Effizienz und Sicherheit des Clearings und standardisierten Collateral Managements und der Abwicklung für besicherte Finanzierungsgeschäfte. integration-factory hat verschiedene Projekte für Eurex Repo durchgeführt.
Zentrale Projekte
Die Helaba ist eine integrierte Universalbank mit starkem regionalem Fokus. Sie ist eng in die Sparkassenorganisation integriert und auch an ausgewählten internationalen Standorten präsent. Als Sparkassenzentralbank in Hessen, Thüringen, Nordrhein-Westfalen und Brandenburg ist die Helaba starker Partner und Dienstleister für 40 Prozent aller deutschen Sparkassen.
Technische Architektur zum Aufbau der Informationsplattform und darauf aufbauende zentrale Projekte
Der Finanzdienstleister Eurex Clearing fungiert als zentrale Gegenpartei und ist innovativ im Bereich Risikomanagement, Client Asset Protection und neue Clearingtechnologien. integration-factory hat verschiedene zentrale Projekte für Eurex Clearing durchgeführt.
Aufbau des zentralen Data Warehouse für STOXX
Die STOXX Ltd. ist ein globaler Anbieter innovativer Index-Konzepte. Die ersten STOXX Indizes wurden 1998 gestartet, unter anderem der EURO STOXX 50 als einer der weltweit meistbeachteten Aktienindizes im Euroraum. integration-factory hat das zentrale Data Warehouse für STOXX entworfen und umgesetzt.
Durchführung verschiedener zentraler Projekte besonders im Aufbau der Informationsplattform
Eurex ist eine Aktiengesellschaft im vollständigen Besitz der Deutsche Börse AG. Als international führende Terminbörse bietet Eurex erstklassige Markteffizienz und -integrität kombiniert mit einem globalen Portfolio an Produkten und Dienstleistungen. integration-factory hat verschiedene zentrale Projekte für Eurex durchgeführt.
Konzeption und Realisierung der Integrationsplattform ETL Factory für den Austausch von Daten zwischen verschiedenen operativen Systemen
Die Deutsche Bank AG ist das nach Bilanzsumme und Mitarbeiterzahl größte Kreditinstitut Deutschlands. Besonderes Gewicht legt die Bank auf das Investmentbanking mit der Emission von Aktien, Anleihen und Zertifikaten. integration-factory hat verschiedene zentrale Projekte für die Deutsche Bank im Rahmen des Aufbaus der ETL Factory durchgeführt.
Aufbau des zentralen Data Warehouse CRiS für das CRM der Daimler AG
Daimler vertreibt Fahrzeuge und Dienstleistungen in nahezu allen Ländern der Welt und hat Produktionsstätten in Europa, Nord- und Südamerika, Asien und Afrika. integration-factory hat das zentrale Data Warehosue CRiS für das Customer Relationship Managements für die Daimler AG aufgebaut.
Systementwurf und technische Architektur zum Aufbau der Informationsplattform
Die Gruppe Deutsche Börse ist eine der größten Börsenorganisationen der Welt. Sie organisiert integre, transparente und sichere Märkte für Investoren, die Kapital anlegen, und für Unternehmen, die Kapital aufnehmen. integration-factory hat verschiedene zentrale Projekte für die Deutsche Börse AG durchgeführt.
Zentrale Projekte
Die Hamburger Sparkasse AG (Haspa) ist die führende Bank für Privatkunden und mittelständische Firmenkunden in der Metropolregion Hamburg.
Grundlegende Design-Richtlinien, Standardisierung & Normalisierung für Stamm- und Transaktionsdaten im Börsenhandel etc.
Die Börse Stuttgart ist die Privatanlegerbörse und der führende Parketthandelsplatz in Deutschland. Private Anleger können in Stuttgart Aktien, verbriefte Derivate, Anleihen, ETFs, Fonds und Genussscheine handeln – mit höchster Ausführungsqualität und zu besten Preisen. integration-factory hat verschiedene zentrale Projekte für die Börse Stuttgart durchgeführt.
Aufbau der Informationsplattform, dazu Systementwürfe, technische Architektur, Datenintegrationsprozessen und weitere zentrale Projekte
Die European Energy Exchange (EEX) ist der führende Marktplatz für Energie und energienahe Produkte in Europa. Sie entwickelt, betreibt und vernetzt sichere, liquide und transparente Märkte für Energie- und Commodity-Produkte. integration-factory hat verschiedene zentrale Projekte für die EEX AG durchgeführt.
Verschiedene zentrale Projekte im Bereich Datenmodell und Datenintegration
Die DZ BANK ist die Zentralbank der Volksbanken Raiffeisenbanken und ihr Auftrag ist es, die Geschäfte der vielen eigenständigen Genossenschaftsbanken vor Ort zu unterstützen und ihre Position im Wettbewerb zu stärken. integration-factory hat verschiedene zentrale Projekte für die DZ BANK AG durchgeführt.
Aufbau einer konzerneigenen Big Data Plattform
Als eine führende, international agierende Geschäftsbank mit Kernmärkten in Deutschland und Osteuropa ist die Commerzbank ein kompetenter und fairer Partner ihrer Privat- und Firmenkunden. Im Rahmen ihrer Digitalisierungsstrategie möchte die Commerzbank bis Ende 2018 eine konzerneigene Big Data Plattform aufbauen. Hier führt integration-factory verschiedene Projekte mit 100 weiteren Spezialisten durch.
Aufbau eines zentralen, unternehmensweiten Data Warehouses
Im Projekt BI@Böllhoff vereinheitlichen wir Reporting Prozesse und Services. Dazu wird ein zentrales, unternehmensweit harmonisiertes Data Warehouse auf der Basis von Microsoft SQL Server und Informatica PowerCenter aufgebaut.
Erstellung einer neuen Dateneingangsschicht mit Informatica Power Center
Als einer der führenden Informationsdienstleister für die Finanzwirtschaft liefert die WM Gruppe seit mehr als 70 Jahren maßgeschneiderte Datenlösungen und Informationen entlang der gesamten Prozesskette ihrer Kunden. Im Projekt „EDDy_neu“ erstellt integration-factory eine neue Dateneingangsschicht mit Informatica Power Center.
Sie wollen Ihre Datenplattform neu designen oder haben Fragen zu unserem Ansazt? Gerne diskutieren wir dies mit Ihnen.
Ansprechpartner
Stefan Sander
+49 (0) 69-25669269-0
info@integration-factory.de
KONTAKT
integration-factory GmbH & Co. KG
Windmühlstraße 2
60329 Frankfurt am Main
Fon +49 (0) 69-25669269-0
Fax +49 (0) 69 25669269-19
info@integration-factory.de
TECHNOLOGIE
© 2022 integration-factory GmbH & Co. KG. All Rights Reserved.














